Pengumpulan data, pengolahan dan analysis data adalah komponen penting dalam rangkaian kegiatan PKL Poltekkes Padang. Pengolahan data dalam PKL terpadu mengalami kemajuan mulai dari manual, semi komputerisasi dan tahun 2011 ini PKL Terpadu Poltekkes Padang melaksanakan pengolahan dana analisis data secara komputerisasi secara penuh.
KETENTUAN UMUM
- 1. Data yang dikumpulkan terdiri dari data keluarga dan individu. Data individu meliputi segmen : balita, anak sekolah, remaja, dewasa, lansia, bumil dan busui.
- 2. Kerangka sampling adalah keluarga yang memiliki balita.
- 3. Kebijakan dalam hal segmen adalah semua anggota rumah tangga dijadikan responden. Datanya disesuaikan dengan jumlah yang ada dalam rumah tangga. Konsekwensinya adalah dalam 1 sampel rumah tangga harus ada minimal 1 orang balita, semua anak sekolah, remaja, bumil, busui, lansia dijadikan segmen ang akan diwawancarai. Dengan demikian jumlah anak sekolah akan lebih banyak dari sampel, akan tetapi remaja atau bumil lebih sedikit dari sampel.
- 4. Kuesioner terdiri dari 2 bagian (keluarga dan individu)
- 5. Entri data kuesioner dilakukan dengan Epidata dan analisis dengan SPSS. Data konsumsi gizi dengan Aplikasi Microsoft Excel, dan data antropometri menggunakan software yang dikeluarkan oleh WHO disebut WHO ANTHRO 2005.
- 6. Entri data dipisahkan antara keluarga dan individu, dan kuesioner individu dientri sesuai segmen, sehingga jumlah template entri data terdiri dari : (dalam kurung adalah nama file)
a. Data Keluarga (Form 1.keluarga)
b. Data Individu, terdiri dari :
· Data Kesakitan dan Kematian (2a.Individu A-E.rec)
· Data Balita (2b.BALITA.rec)
· Data Lansia (2c.LANSIA.rec)
· Data Remaja (2d.REMAJA.rec)
· Data UKS dan Anak Sekolah (2e. UKS dan Anak Sekolah.rec)
· Pengukuran Bumil (2f. BUMIL.rec)
7. Data frekuensi konsumsi kelompok Pangan dan konsumsi zat gizi diolah tersendiri menggunakan Microsoft Excel, kemudian diproses sedemikian rupa sehingga menjadi sebuah file berformat SPSS (FFQ.SAV). Jangan lupa memeriksa kesesuaian kode sampel. Penanggung jawab adalah anggota kelompok dari Jurusan Gizi.
8. Data Status Gizi Balita diolah menggunakan software WHO Anthro2005, diproses sedemikian rupa sehinggan menjadi sebuah file berformat SPSS (Antro.SAV). Penanggung jawab adalah anggota kelompok dari Jurusan Gizi.
9. Setiap kelompok PKL harus mengentri 9 jenis file data sesuai uraian di atas.
10. Semua file harus bisa digabung (merge) dalam SPSS, maka dari itu setiap file harus memiliki 1 buah field kode sebagai key variable untuk menggabungkannya.
11. Dalam entri data, masing-masing variabel ada yang sudah siap dientri dalam bentuk kategori yang dibutuhkan, dan ada yang masih dalam bentuk Total Skor. Bahkan ada variabel yang dientri masih dalam bentuk pertanyaan satu persatu. Untuk itu diperlukan proses Transformasi Data, seperti conpute dan Recode.
12. Dalam entri data, setiap kelompok diperbolehkan mendisain check agar data yang terentri nanti terbebas dari kesalahan, namun dilarang merubah kuesioner (field), agar datanya bisa digabung antar kelompok.
13. Hati-hari dalam penyamaan kode pada setiap file yang terhubung masing-masing segmen.
14. Sebelum data diolah harus dilakukan cleaning data terhadap kesalahan/kekeliruan dalam entri data. Setiap ditemukan record yang tidak lengkap, tidak konsisten dan out of range harus dilakukan pengecekan kembali ke kuesioner, bahkan jika diperlukan dilakukan pengecekan ke lapangan (ke rumah responden).
15. Bagi yang membutuhkan master aplikasi yang dibutuhkan seperti Epidata, SPSS, WHO Antro dan lain-lain, disediakan dalam sebulah file installer di dalam sebuah CD yang dibagikan ke semua kelompok. SPSS yang disediakan dalam Installer ini adalah versi 11.5 yang sesuai untuk Sistem Operasi Windows XP. Bagi mahasiswa yang memiliki laptop dengan Sistem Operasi Windows Vista dan Windows Seven harus mencari sendiri versi SPSS yang sesuai (versi 15 atau lebih tinggi).
16. Panduan ini membahas contoh-contoh penggabungan data, transformasi data dan analysis data.
EDITING
Editing adalah melakukan perbaikan pada kuesioner hasil wawancara untuk mengecek kejelasan tulisan, kelengkapan isian dan kebenaran isi (misalnya range data). Editing harus dilakukan sesegra mungkin setelah wawancara. Dilakukan [pada malam hari pada hari-H wawancara. Setelah editing dilakukan, kuesioner ditanda tangani dan kemudian diberikan ke salah satu teman sekelompok untuk dilakukan juga editing dan ditanda tangani juga. Terakhir diserahkan ke Pembimbing untuk diperiksa dan ditanda tangani. Kuesioner yang boleh dientri setelah ada 3 tanda tangan (Pewawancara, Editor dan Pembimbing). Hal ini dilakukan untuk mengurangi kesalahan dalam data entri, menghindari GIGO (garbage in garbage out).
CODING
Dalam hal ini koding termasuk ke dalam editing, yaitu memasukkan kode (skor) ke dalam kotak yang disediakan di bagian kanan setiap pertanyaan. Untuk variabel komposit, langsung dihitung total skor setiap variabel. Untuk variabel dimana total skor sudah dihitung, maka yang akan dientri adalah optionnya (disesuaikan dengan template yang sudah ada).
ENTRI DATA
Data dientri berurutan dari keluarga dan individu sesuai pemuatan dalam kuesioner. Setelah kuesioner keluarga dintri (1. Keluarga.rec) langsung dientri data individunya setiap segmen secara berurutan. Apabila dalam keluarga tersebut ada 2 balita, selesaikan entri data balita keduanya sesudah itu baru mengentri data segmen berikutnya. Demikian juga jika terdapat 3 anak sekolah, entri ketiganya lebih dulu baru kanjut ke segmen bumil dan seterusnya.
Data FFQ (konsumsi balita) dan antropometri (BB dan TB) dientri dengan software yang terpisah, dengan menyiapkan kode yang sama dengan keluarga asal setiap segmen untuk penggabungan data sewaktu pengolahan nantinya. Untuk data konsumsi gizi balita diambil balita yang sudah disapih, minimal 30 sampel tiap kelompok PKL.
EXPORT DATA
Oleh karena entri data dilakukan dengan Epidata, sementara analisis dengan SPSS, maka perlu dilakukan export data. Caranya : di dalam Epidata pilih Menu no.6 EPORT DATA, lalu pilih pilihan SPSS. Arahan pilihan pada file yangg akan diekport.
Setelah jendela dialog muncul, klik OK
Hasil export Epidata ke SPSS menghasilkan file berekstensi .SPS (SPSS Syntax). Sinyax yang dihasilkan di jalankan (Run) di SPSS, akan menghasilkan database berformast SPSS ).SAV). Caranya : buka SPSS, kemudian Open File, Pilih Syntax, dan arahkan ke folder hasil export Epidata, pilih file. Maka akan terbuka file syntax dalam bentuk textfile. Run Syntax tersebut.
Pilih pada menu di dalam jendela Syntax tersebut
Run, lalu klik
All.
Hasil running syntax adalah file data SPSS (untitled), Simpan dan beri nama sesuai dengan karakteristik datanya. Misalnya file KELUARGA.SAV.
Semua file dieksport seperti prosedur di atas.
CLEANING DATA
Cleaning data adalah suatu aktivitas memeriksa data dari ketidaklengkapan, ketidak-jelasan, dan out of range. Cleaning data. Prosedur cleaning data berbeda antara data numeric dan data kategorik. Data kategorik dilihat kelengkapan kategori, apakah sudah semua sampel didistribusikan ke dalam kategori yang ada. Atau apakah klategori data yang terbentuk sudah sesuai dengan yang didefinisikan dalam kerangka konsep atau belum. Misalnya variabel kecamatan (nama field kec) : Apakah sudah semua sampel diisikan dari kecamatan mana sampel itu.
Perinta untuk memeriksanya bisa digunakan :
Analyze - Descriptive Statistics - Frequencies
Masukkan field kec, kemudian klik OK. Lihat aoutpu yang dihasikan oleh SPSS. Apabila ada yang missing, atau ada kode kecamatan selain dari 1, 2 atau 3, maka bisa dicari dengan mengurutkan data (sort). Perintahnya Pada menu DATA, pilih SORT CASES. Masukkan field kec, kemudian pilih sort order Accending (menaik. Dengan pilihan accending, maka record missing akan terletak paling atas.
Langkah berikutnya adalah mengklarifikasi record bersangkutan ke kuesioner fisik, kemudian mengeditnya secara manual di SPSS.
Perintah Frequencis juga dipakai untuk analisis Univariate untuk data kategorik. Perintah frequencies juga bisa dipakai untuk menghitung detail dari data numerik seperti median dan modus, dengan cara menspesikasikan hitungan pada pilihan statistics (dalam dialog frequencies)
Trasformasi Data
Transformasi atau merubah format data yang ada ke format lain, misalnya data numerik dijadikan data kategorik atau data kategorik dijadikan lebih sederhana kategorinya. Perintah yang dipakai untuk ini adalah Recode. Sementara untuk menghitung jumlag skor dari variabel komposit digunakan perintah Compute.
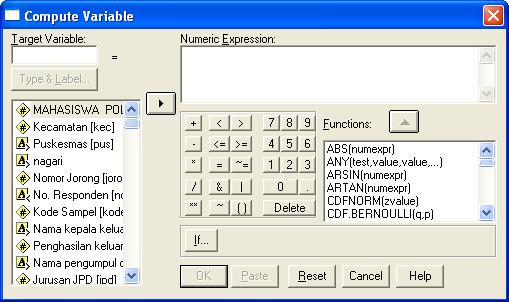
Compute ~ hitung : Transfor - Compute, tampil sbb :
Pada perintah compute digunakan untuk perhitungan. Perhitungan sederhana yang diperlukan untuk mengolah data PKL iini adalah menjumlah skor dari beberapa pertanyaan menjadi satu nilai (disebut variabel komposit).
Langkah-langkah Compute :
• Buat nama variabel target (target variable) dimana hasil perhitungan akan diletakkan. Klik pada type and Labels untuk mendefinisikan Label dan pemilihan type field (numeric). Klik OK untuk kembali ke jendela awal.
• Lakukan perhitungan dengan mengklik kalkulator sedrhana yang ada dibawah numeric expression.
Misalkan kita akan mengihutng Jumlah Anggota keluarga dari rincian Jumlah laki-laki (laki2) ditambah perempuan (puan) menghasilkan variabel jak. Cari field laki2 kemudian kirim ke jendela tengah menggunakan tombol panah diatara 2 jendela, kemudian klik tombol tambah pada kalukulator. Cari fiel puan dan kirim ke tengah sehingga di tengah tertulis laki2 + puan. Jika sudah selesai klik OK. Setelah klik OK akan terbentuk field baru (jak) hasil perhitungan.
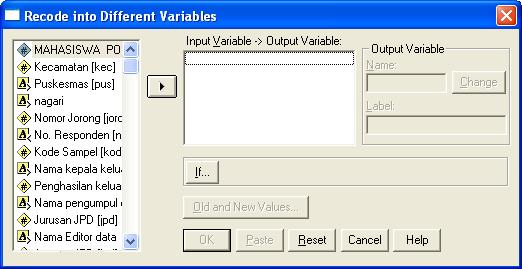
Recode
Recode gunanya adalah untuk mengkategorikan variabel numeric atau menyederhanakan kategori yang sudah ada menjadi lebnih sedikit kategorinya. Perintah recode yang dipakai disini adalah Recode – Into Diffenrent Variable. Dengan Into Different maka akan terbentuk field baru (hasil kategori) bukan menimpa nilai variabel lama.
Langkah-langkah Recode (lihat gambar berikut :
Cari variabel yang akan direcode, masukkan ke dalam menggunakan tombol panah. Definikan nama baru dan label nya di sebelah kanan. Penamaan fiel harus memenuhi ketentua (max 8 digit, tanpa sapasi, tanpa tanda baca, tanpa operasi matematis dan lowecase/huruf kecil). Sebaiknya nama field singkat dan informatif. Setelah New Name dan Label diketik, klik
Change, sehingga tanda tanya di tengah terganti dengan nama field baru yang akan dibuat.
Langkah berikut adalah mendefinisikan kategori. Klik
Old and New Value, tampil spt berikut
Masukkan batas kategori di sebelah kiri (old value) dan masukkan nama kategori di sebelah kanan (New Value). Setelah semua kategori didefinisikan, klik Continue maka akan kembali ke jendela sebelumnya. Untuk mengakhiri proses klik OK. Anda juga dapat mengklik Paste, sehingga perintah yang sudah dibuat akan dimasukkan ke dalam file Teks (Syntax). Cara ini lebih dianjurkan oleh karena sangat memudahkan untuk melakukan pengeditan label dan batas kategori. Satu hal yang sangat penting disini adalah pendefinian Value Labels (istilah kategori data).
Dua keuntungan jika perintah transformasi data disimpan ke dalam file syntax adalah.
1. Memudahkan mendefinisikan Variable Labels
2. Dapat didefinisikan langsung Value Labels
Perintah untk membuat Variable Labels adalah
VARIABLE LABELS [nama field] dalam tanda petik tunggal Nama Variabel, diakhiri dengan titik.
Misalnya kita ingin memberi nama variabel label dan value label untuk contoh hasil tranformasi di atas. Ketikkan baris berikut ini :
VARIABLE LABELS eko2 'Tingkat Ekonomi Keluarga' .
ADD VALUE LABELS eko2 1 'Miskin' 2 'Kaya' .
Jangan lupa menutup baris perinta dengan titik (.)
Jika semua perintah disimpan ke dalam file syntax akan sangat memudahkan dalam melakukan editing. Misalnya mencoba melakukan pengkategorian variabel numerik dengan batas kategori yang berbeda dari parokan ke normatif misalnya, tinggal mengedit file teks (syntax) kemudian di Run syntax yang diedit, selesai dengan sangat cepat.
ANALYSIS BIVARIATE
Analysis bivariate dalam PKL terpadu adalah untuk mencari faktor penyebab dari suatu masalah yang ditemukan. Secara umum analysis bivariate adalah untuk ,mengatahui keterkaitan 2 variabel yang mengacu pada landasan teoritis yang sesuai.
Pada PKL terpadu ini semua variabel dijadikan menjadi 2 kategori. Alasannya adalah berdasarkan kesepakatan bahwa faktor penyebab (istilah lainnya faktor risiko) ditentukan dengan mencari nilao OR (estimasi OR). Walaupun pengumpulan data disain crossectional, namun disepakati dalam mencari faktor penyebab dengan menghitung nilai OR. Perintah yang dipakai untuk ini adalah Crosstabs, dapat dipilih dari menu ANALYZE-DESCRIPTIVE STATISTICS – CROSSTABS, akan tampil sebagai berikut :
Masukkan independen variabel (expossure/faktor risiko) di Row dan Dependen Variabel (outcome) di Colom. Selanjutnya klik Statistics
Pilihan
Risk adlah untuk mengeluaarkan nilai
OR. Klik Continue untuk kembali ke jendela sebelumnya. Kemudian klik Cells untuk menentukan persentase. Pilih Row pada Percentage, karena independen var diletakkan di row
Klik Continue untuk kembali ke jendela sebelumnya dan Klik OK. Bisa juga di-pastekan ke file syntax dan akan ditempatkan di bawah syntax sebelumnya..
Panduan mengolah data Konsumsi klik disini
Panduan Mengolah data Status Gizi klik disini
Penggabungan Data
Penggabungan data merupakan bagian yang sangat penting dalam pengolahan data khususnya dalam analisis bivariate, oleh karena antara variabel independen (penyebab) dengan dependen (dampak terletak pada file yang berbeda. Misalnya antara penyakit dengan status imunisasi terletak pada file yang berbeda. Secara standar, penggabungan data (merge) ada 2 jenis (1) Penambahan recode (
add rcases) dengan struktur file yang sama, dan (2) Penambahan Variabel (
add variables) dengan jumlah record yang sama.
Pada kasus penggabungan data PKL terpadu adalah add variable dengan jumlah record berbeda. Untuk penyelesaian kasus ini strateginya adalah : Buka lebih dulu file dengan jumlah record lebih banyak, kemudian gabungkan dengan file dengan file dengan jumlah record lebih sedikit.
Contoh :
Untuk menggabungkan data Anak Sekolah dengan data keluarga, dimana dalam 1 keluarga bisa saja terdapat 1 atau 2 anak sekolah maka jumlah record dari file Anak Sekolah lebih banyak dibandingkan dengan record data keluarga. Syarat mutlak penggabungan data
Add Variable adalah bahwa di kedua file yang akan digabung harus memuliki 1 file kunci (
key variable) sebagai kunci penggabungan data. Dalam hal ini kita sudah mempersiapkannya sejak dari awal dengan 1 field yaitu
kode.
Langkah-langkah Penggabungan data (penggabungan file) :
- Buka file kedua (file yang jumlah record sedikit). Pada contoh akan emnggabungkan data Anak Sekolah.sav dengan data keluarga.sav, maka data keluarga dibuka lebih dulu.
- Sort file keluarga.sav dengan key kode dan Sort Order Accending.
- Simpan.file keluarga.sav
- Buka file kedua (file dengan record lebih banyak (anak sekolah.sav)
- Sort file anak sekolah.sav dengan kunci kode dengan pilihan sort order Accending.
- Simpan file anak sekolah.sav.
- Gabung kedua file pada saat file anak sekolah sedang terbuka dengan memilih menu Datas - Merge File, sepertitampilan berikut ini. Pertama pilih pada menu Data lalu pilih Merge File, lalu di dalamnya pilih Add Variables
Klik (beri tanda check) pada Match case..... Klik field kode, lalu klik tanda padah, sehingga field kode pindah ke jendela key variables. Lalu klik OK.
Biasanya akan muncul warning bawa SPSS hanya akan menggabung data yang telah disort menurut key variable tertentu. Abaikan saja warning tersebut dengan mengklik OK
File yang sudah digabung bisa disimpan dengan nama yang berbeda, atau tidak disimpan, dan dilakukan penggabungan saat dibuthkan saja. Untuk lebih 'aman' data disimpan dengan nama kombinas file awalnya (misalnya keluarga sekolah.sav).
SELAMAT BEKERJA